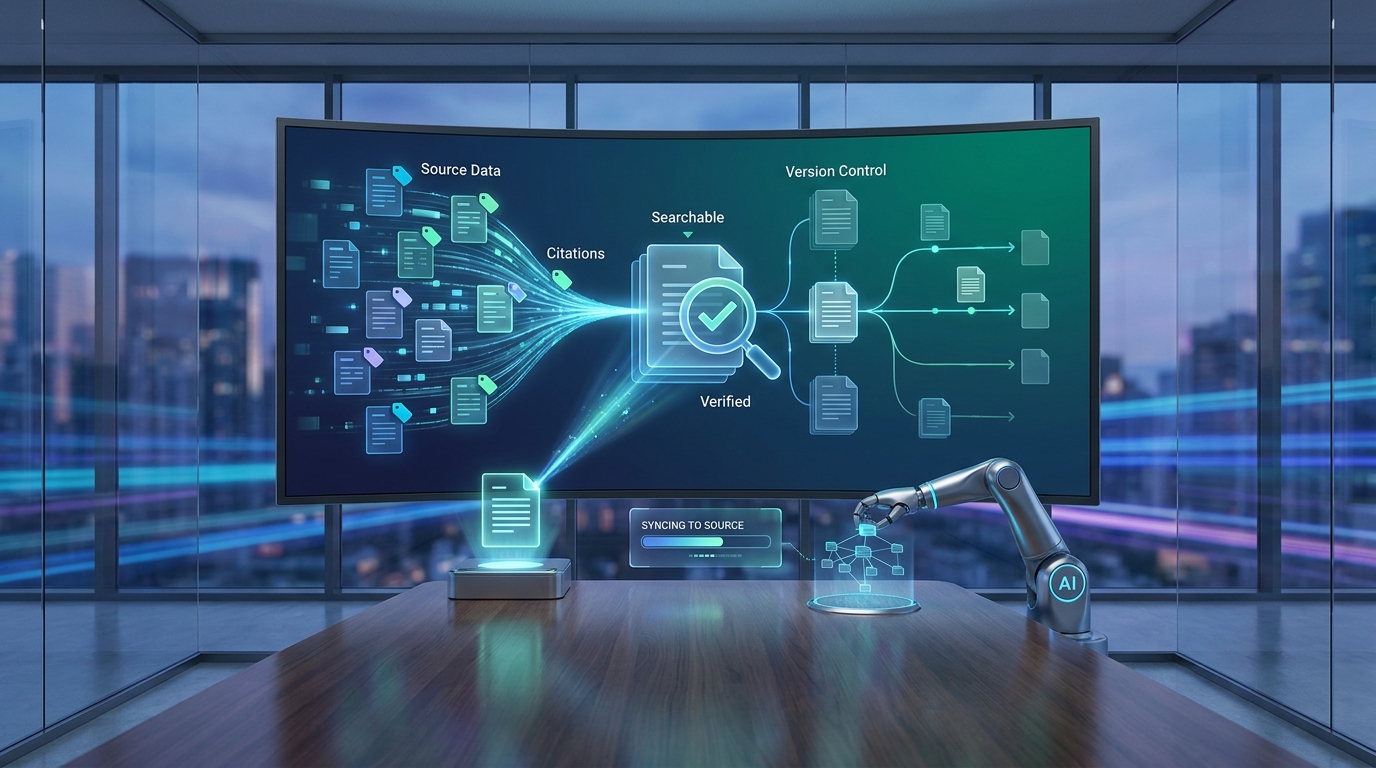
AI documentation generation is easy to demo—and hard to operationalize. The moment your code, APIs, and configs change, you risk documentation drift: pages that look right but no longer match what ships.
This guide lays out a practical, docs‑as‑code automation approach to RAG documentation (retrieval‑augmented generation) that stays tethered to your source of truth, with versioned documentation, AI documentation verification, and an audit trail you can defend.
TL;DR (what you’re building)
- Source‑connected pipeline: docs are generated from repos/specs/configs (not memory).
- Version integrity: every page is tied to a branch/tag/commit—no mixed‑version “Franken‑docs.”
- Citation‑backed outputs: each technical claim links to a specific source + anchor.
- Verification before publish: automated checks (schema/test/compile/API) catch bad instructions.
- Measurable quality: you track freshness, accuracy signals, and search success over time.
Assumptions (so the advice is usable)
This playbook assumes you have:
- A git‑based workflow for code and (ideally) docs
- One or more authoritative specs (OpenAPI/AsyncAPI, JSON Schema, config schema) for at least some surfaces
- A docs site that can ingest Markdown/MDX (common in docs‑as‑code stacks), plus optional JSON for indexing
- A team that can support code owner review for high‑risk doc changes (even if AI drafts them)
If you don’t have specs or schemas, you can still use the approach—but your “verification” will lean more heavily on compilation/tests and human review.
Definition of done (targets you can actually manage)
Before you automate anything, define what “good” looks like. Here’s a concrete baseline you can adopt and tune:
- Freshness SLA (median lag from merged change → docs updated)
- P0 surfaces (auth, payments, incident runbooks): ≤ 4 hours
- P1 surfaces (core APIs/SDKs): ≤ 24 hours
- P2 surfaces (internal tooling/how‑tos): ≤ 72 hours
- Citation coverage: ≥ 95% of technical claims have a source + anchor
- Verification pass rate: ≥ 90% of generated doc PRs pass automated checks without edits
- Search success rate (for AI search/RAG): ≥ 70% “answer found + cited + correct version” on a weekly evaluation set
These are operational targets—not universal truths. The point is to make drift and quality measurable.
Step-by-step architecture (Input → Processing → Retrieval → Generation → Verification → Publishing → Monitoring)
A production pipeline for AI documentation generation usually needs the following components (the exact shape varies by stack):
- Input (source of truth ingestion)
- Repos: code, READMEs, comments, ADRs
- Specs: OpenAPI/AsyncAPI, schemas
- Operational sources (when appropriate): configs, runbooks, sanitized logs
- Processing (chunking + metadata enrichment)
- Retrieval (versioned indexing)
- Generation (structured outputs + citations)
- Verification (automated checks + human review gates)
- Publishing (docs-as-code commit + site build)
- Monitoring (quality metrics + drift detection + regression tests)
This structure aligns with industry guidance that emphasizes: writing docs to be retrievable in chunks and including version context (kapa.ai), integrating docs workflows with CI/CD triggers (Docsie), and maintaining human QA and transparency for AI-produced content (Write the Docs) (kapa.ai, Docsie, Write the Docs).
Source of truth boundaries and governance (where accuracy actually comes from)
“Source of truth” is not a vibe. It’s a priority order with owners.
1) Define what counts as source of truth
Use a simple hierarchy (example):
- Specs and schemas (OpenAPI/AsyncAPI/JSON Schema) for contract surfaces
- Released code (tagged commits, release branches) for implementation details
- Configs and feature flags (schema-validated) for runtime behavior
- Runbooks (owned by on-call teams) for operational procedures
- Tickets/ADRs for rationale and future intent (never for current behavior unless verified)
2) Resolve conflicts explicitly
When sources disagree, decide your rule up front:
- Contract wins for external behavior: if the OpenAPI says one thing and code does another, you either fix the spec or label the docs as “implementation differs; verified behavior is X” with citations.
- Release branch wins for versioned docs: never generate
v2.2docs frommain. - Runtime sources must be sanitized: logs/configs can inform docs, but should not override specs unless you have a controlled verification step.
3) Assign ownership
- Doc owners map to code owners for code-adjacent pages.
- Establish a simple SLA: e.g., P0 doc PR review within 1 business day.
- Define an escalation path: on-call lead or engineering manager for P0 breakages.
RAG vs fine-tuning for documentation (when to use which)
You’ll see two common approaches:
- RAG (retrieval-augmented generation): the model answers using retrieved chunks from your doc corpus. You control “truth” by controlling what is retrieved and cited.
- Fine-tuning: you train a model on examples so it writes in a certain style or performs a specific task more reliably.
Practical guidance:
Use RAG when
- You need current answers tied to versioned sources
- You want citations to specific repo paths/sections
- Your content changes frequently (APIs, configs, runbooks)
This aligns with kapa.ai’s emphasis on structuring docs for chunk-level retrieval with enough context and version info per section (kapa.ai).
Use fine-tuning when
- You need consistent formatting and tone across thousands of outputs
- You have stable patterns (e.g., “turn OpenAPI into reference pages in our house style”)
- You can curate high-quality training examples and manage licensing (see Legal/IP)
Most teams end up with RAG for facts + templates/schemas for structure, and only selectively fine-tune if the ROI is clear.
Documentation drift: what it is, why it happens, how to measure it
Documentation drift is the gap between what your docs say and what your system actually does (for a specific version).
Common causes
- Code/spec changes without doc updates
- Version leakage (retrieving
mainchunks while generatingv2.2pages) - Partial indexing (some folders/specs weren’t ingested)
- Citation rot (links/anchors no longer point to the referenced lines)
A drift measurement formula you can run weekly
Pick a sample of pages and define a “staleness” rule (e.g., references an endpoint that changed).
- Drift rate (%) = (Number of stale pages / Number of pages sampled) × 100
- Median doc lag = median(time of source change → time doc update merged)
Docsie recommends integrating doc updates with your repo and CI/CD triggers to keep documentation synchronized with code changes—use that as the mechanism to reduce lag, then measure the impact using the formulas above (Docsie).
Chunking for RAG documentation (retrieval that stays in bounds)
Chunking isn’t about page layout—it’s how you make retrieval precise enough to support citation-backed answers.
kapa.ai explicitly recommends writing docs so sections are independently understandable and include version information, because those sections become the units stored and retrieved (often from a vector database) (kapa.ai).
A practical chunking baseline (tune by content type)
Start with:
- 200–500 words per chunk as a starting point for many how‑tos and explanations
- Prefer semantic boundaries (a task, decision, or error mode) over strict word counts
- Ensure each chunk is self-contained (no “as mentioned above” dependencies)
Word count is a proxy. In practice you’ll tune by tokens, model context window, and how repetitive your prerequisites are.
Add a retrieval header (compact, machine-friendly context)
A retrieval header is a short preamble that reduces ambiguity during retrieval—especially when you have similar endpoints or flags across versions.
Example retrieval header (used inside the chunk):
Component: Billing API
Doc type: How-to
Applies to:>=2.3.0 <2.4.0
Prereqs: OAuth client credentials;billing.writescope
Primary sources:services/billing/routes/invoices.ts+openapi/billing-v2.3.yaml
Chunk by user intent
Good boundaries:
- Create invoice
- Handle validation errors
- Idempotency + retries
Avoid splitting a single procedure across multiple chunks unless you repeat the minimum context in each.
Metadata that improves filtering (and reduces version leakage)
Attach metadata you can actually filter on:
component:billing-apidoc_type:how_to | reference | troubleshootingversion:2.3.0version_range:>=2.3.0 <2.4.0source_paths:["services/billing/routes/invoices.ts", "openapi/billing-v2.3.yaml"]api_endpoint:POST /v2/invoiceslanguage:ts
If you care about “answer engine optimization,” define it plainly: structuring content so AI search and RAG can retrieve the right chunk and cite it, measured by higher answer success and fewer “wrong version” responses.
How to version-control AI-generated documentation (without Franken-docs)
Versioning has two jobs:
- Retrieval returns the right version
- Generation produces outputs that are internally consistent for that version
Option A: Separate indexes per release line (lower leakage risk)
Common pattern:
main→ “next” docsrelease/2.3→ stable docsrelease/2.2→ maintenance docs
Benefits:
- Strong isolation; fewer wrong-version retrievals
- Citations map cleanly to commit hashes
Costs:
- More indexing and storage overhead
- More ops complexity
Option B: Single index + strict metadata filters (cheaper, higher discipline)
Benefits:
- Lower cost and simpler ops
Risks:
- A filter bug or missing metadata can leak wrong-version chunks
Option C: Snapshotted per-release corpus + hybrid search (balanced)
- Build a release snapshot corpus at cut time
- Use lexical + vector retrieval
This can reduce re-embedding churn while still supporting reliable release docs.
Decision table: index strategy trade-offs
| Strategy | Cost | Latency | Wrong-version risk | Operational overhead | When it fits |
|---|---|---|---|---|---|
| Per-branch indexes | High | Medium | Low | High | Fast-moving repos; strict version correctness |
| Per-release-line indexes | Medium | Medium | Low–Medium | Medium | Multiple supported releases |
| Single index + filters | Low | Low | Medium–High | Low | Single supported release; strong metadata discipline |
| Release snapshots | Medium | Low | Low | Medium | Predictable release cadence; compliance-friendly |
Incident vignette (why this matters)
A team publishes a runbook update for v2.3 that changes retry behavior for a billing job (new idempotency key requirement). An engineer on-call searches the docs during an incident—but retrieval pulls a main chunk describing the next release. They apply the wrong mitigation, causing duplicate invoice attempts.
Branch-aware retrieval (or per-release indexes) prevents this class of error by constraining what can be retrieved for release/2.3.
How to add citations to AI-generated docs (make it auditable)
In AI-produced technical docs, citations are operational: they’re how you audit claims and debug wrong outputs.
Docsie highlights transparency practices like source links in AI documentation workflows, and Write the Docs emphasizes human review and quality control for reliability (Docsie, Write the Docs).
A minimum viable citation payload
For each non-trivial technical claim, capture:
- Source: repo path / spec URL / ADR
- Anchor: line range, section ID, or JSON pointer
- Commit/tag: exact revision used
- Retrieved chunk ID: so you can reproduce the generation
- Verification status: pass/fail + check name
Avoid pretending you have a model “confidence score” unless you can define how it’s computed and calibrated. In practice, a verification result is usually more actionable than a probability.
Require citations for “2 a.m. claims”
Always cite:
- default values
- timeouts/retry behavior
- error codes and causes
- permission scopes
- breaking changes and deprecations
If it can change production behavior, it must be traceable.
How to verify AI documentation against source code (and specs and runtime)
Generative output is probabilistic. Your release process can’t be.
Verification is the difference between “looks correct” and “provably anchored to a versioned source.” Write the Docs explicitly frames AI as a drafting accelerator that still requires quality control (Write the Docs).
InfoWorld also notes the opportunity to use runtime signals (logs/configs) to keep documentation current—when handled carefully (InfoWorld).
Verification checklist (what to check)
- API correctness
- endpoint paths
- required headers
- request/response fields
- status codes
- Example code correctness
- imports and package names
- symbol existence and signatures
- compile/type-check (when feasible)
- Behavioral claims
- retries/backoff
- idempotency rules
- rate limits
- caching semantics
- Operational guidance
- config keys + defaults
- feature flag names
- deployment steps
- runbook actions
Verification techniques that work
- Static verification
- parse OpenAPI/AsyncAPI and compare documented endpoints/fields
- scan code for symbol existence/signatures
- validate config keys against schemas
- Runtime verification (when safe and available)
- smoke-test example requests against staging
- run CLI commands in a sandbox
- confirm referenced log messages/error codes exist
- Human review
- treat the output as a PR
- route to code owners
- require sign-off for P0/P1 surfaces
Security and compliance (secrets, PII, access control, retention)
If you ingest repos, specs, and logs, you’re handling sensitive data by default.
Minimum controls to put in place:
- Secrets handling
- Block secrets from ingestion (pre-commit secret scanning; exclude
.env, vault exports) - Redact secrets in any examples generated from configs
- Block secrets from ingestion (pre-commit secret scanning; exclude
- PII in logs
- Don’t ingest raw logs by default
- If you must, require a sanitization pipeline (PII redaction) and strict retention
- Access control
- Indexes should inherit repo permissions (no broad “everyone can search everything”)
- Separate environments: dev/staging/prod indexes
- Auditability
- Keep an audit log of what sources were ingested, when, by whom, and what was published
- Retention
- Define a retention window for embeddings and raw chunks, especially if sourced from incident data
If you operate under SOC 2 / ISO-style controls, treat the doc pipeline like any other production system: least privilege, change logs, and reviewable artifacts.
Cost and performance considerations (what actually blows up)
Costs typically come from:
- Indexing volume (number of chunks × versions)
- Re-embedding cadence (how often you rebuild embeddings)
- CI runtime for verification (compile/tests/smoke calls)
Practical guardrails:
- Re-embed only what changed (diff-based chunk rebuild)
- Prefer per-release-line indexes over per-branch if you have many branches
- Cache retrieval and generation results for unchanged inputs (commit hash + prompt + schema)
- Split verification into tiers:
- Fast checks on every PR (schema validation, citation completeness, link check)
- Heavier checks nightly (compile matrix, staging smoke tests)
Failure modes (and how to detect and contain them)
These are the issues that show up after the first successful demo.
1) Stale embeddings
Symptom: retrieval returns old behavior after a change.
Mitigation:
- diff-based re-indexing
- index build timestamps + alerts when “source updated but index not updated”
2) Partial indexing
Symptom: generation misses critical constraints because a folder/spec wasn’t ingested.
Mitigation:
- ingestion manifests (what paths/specs must be present)
- CI check: fail if required sources are missing
3) Version leakage
Symptom: v2.2 page cites main behavior.
Mitigation:
- hard retrieval filters on
version_range - separate indexes per release line for critical surfaces
- automated test queries that try to “break” version boundaries
4) Citation rot
Symptom: citations point to moved lines/renamed files.
Mitigation:
- cite by commit + stable anchors when possible
- link checks that validate anchors and paths
5) Verification gaps
Symptom: outputs pass checks but are still wrong (because you didn’t test the right thing).
Mitigation:
- expand verification based on incident learnings
- keep a regression suite of “doc failures we never want again”
Tooling integration: how this fits docs-as-code stacks
You don’t need to rebuild your documentation platform. Integrate at the artifact level.
Common integration patterns
- Generate Markdown/MDX pages into the same repo as your docs
- Store machine-readable JSON alongside pages for indexing/search tooling
- Use frontmatter for metadata (
version_range,component,doc_type)
A Doc Gate pattern (CI step that blocks risky drift)
Below is a simplified pseudo-pipeline showing what “doc gates” can check:
docs:
steps:
- name: Build doc corpus
run: docs build-corpus --rev $GIT_SHA
- name: Enforce citation completeness
run: docs check-citations --min-coverage 0.95
- name: Verify against OpenAPI
run: docs verify-openapi --spec openapi/billing-v2.3.yaml
- name: Type-check code examples
run: docs verify-examples --lang ts --mode typecheck
- name: Link and anchor check
run: docs check-links --fail-on-broken
- name: Publish preview
run: docs publish --target preview
Tune gates by severity tier:
- P0 pages: block release if verification fails
- P2 pages: allow merge but open an issue + alert owner
Concrete end-to-end example (Billing API): repo/spec → chunk → index → generate → verify → PR → publish
This is what “source-connected, versioned, verifiable” looks like in practice.
1) Inputs
- Repo path:
services/billing/routes/invoices.ts - Spec:
openapi/billing-v2.3.yaml - Target: docs for
release/2.3at commita1b2c3d
2) Generated chunk (example)
Chunk ID: billing-api__create-invoice__v2.3
Component: Billing API
Doc type: How-to
Applies to:>=2.3.0 <2.4.0
Prereqs: OAuth client credentials;billing.writescope
Primary sources:openapi/billing-v2.3.yaml(CreateInvoice) +services/billing/routes/invoices.tsCreate an invoice
Send a
POST /v2/invoicesrequest with an idempotency key. If you retry the same request, reuse the same key to avoid duplicate invoices.Request
curl -X POST "$BASE_URL/v2/invoices" \ -H "Authorization: Bearer $TOKEN" \ -H "Idempotency-Key: 6f5c2a3e-..." \ -H "Content-Type: application/json" \ -d '{"customerId":"cus_123","amountCents":1299,"currency":"USD"}'Responses
201: invoice created400: validation error (see error codes below)
3) Metadata object (stored with the chunk)
{
"id": "billing-api__create-invoice__v2.3",
"component": "billing-api",
"doc_type": "how_to",
"version": "2.3.0",
"version_range": ">=2.3.0 <2.4.0",
"api_endpoint": "POST /v2/invoices",
"source_paths": [
"openapi/billing-v2.3.yaml",
"services/billing/routes/invoices.ts"
],
"commit": "a1b2c3d"
}
4) Citation payload (what makes it auditable)
{
"claim": "POST /v2/invoices supports Idempotency-Key to prevent duplicates on retries",
"sources": [
{
"type": "openapi",
"path": "openapi/billing-v2.3.yaml",
"anchor": "#/paths/~1v2~1invoices/post/parameters/Idempotency-Key",
"commit": "a1b2c3d"
},
{
"type": "repo",
"path": "services/billing/routes/invoices.ts",
"anchor": "L120-L168",
"commit": "a1b2c3d"
}
],
"verification": {
"openapi_match": "pass",
"example_smoke_test": "pass"
}
}
5) Verification output (pass/fail with reasons)
- OpenAPI comparison: PASS (endpoint + header documented in spec)
- Example request smoke test (staging): PASS (201)
- Link/anchor check: FAIL (repo file moved;
L120-L168anchor invalid)
Result: PR stays open until citations are updated to a valid anchor. That’s how you prevent “citation-backed” from degrading over time.
6) PR and publish
- The generator commits Markdown/MDX + JSON artifacts
- CI runs doc gates
- Code owner approves
- Site build publishes for
release/2.3
Evaluation and monitoring: a simple scoring framework (ACV Score)
To keep this from becoming a one-time cleanup project, track quality continuously.
ACV Score (Accuracy, Coverage, Version integrity)
Score each doc page (or chunk set) weekly:
- A — Accuracy signals (0–5)
- 5: passes schema/spec checks + examples verified
- 3: citations present but verification incomplete
- 0: uncited technical claims
- C — Citation coverage (0–5)
- 5: ≥95% of technical claims cited
- 3: 80–94%
- 0: <80%
- V — Version integrity (0–5)
- 5: all sources/citations match target branch/tag
- 3: mixed sources detected but flagged
- 0: wrong-version citations in published docs
Ship threshold: ACV ≥ 12/15 for P1, ≥ 14/15 for P0
Monitoring loop
- Weekly evaluation set (20–50 queries): measure “answer success + correct version + citations”
- Drift report: drift rate + median lag
- Regression suite: add a test whenever a doc mistake causes an incident or near-miss
What this will and won’t solve
This will solve
- Keeping docs tied to a commit/tag with reproducible citations
- Preventing mixed-version retrieval when version controls are enforced
- Catching obvious wrongness via spec/schema/test/compile verification
This won’t solve (without additional work)
- Missing specs: if there’s no contract, you’ll need stronger runtime tests and review
- Ambiguous product behavior: AI can’t resolve contradictions without governance decisions
- Poor operational hygiene: if configs/logs aren’t reliable or sanitized, don’t ingest them
Write the Docs is clear on this broader point: AI can accelerate drafting, but quality control and human oversight remain essential (Write the Docs).
Legal and IP considerations (don’t skip this)
Before you train, fine-tune, or even index:
- Licensing: ensure you have the rights to use internal and third-party code/specs in training or model customization.
- Attribution: if you reproduce code snippets, preserve required headers and attribution where applicable.
- Data boundaries: treat customer data and proprietary logic as restricted; avoid using it in training unless explicitly approved and controlled.
If you’re unsure, route the plan through legal/security before turning on ingestion at scale.
Where J77 fits (capabilities you should validate)
If you’re evaluating a platform (including J77) to support this pipeline, validate it against acceptance tests—not marketing language.
Capability checklist (with acceptance tests)
- Verification layer
- Acceptance test: Given a doc claim about an endpoint field, the system can verify it against OpenAPI and fail the build when it doesn’t match.
- Structured output
- Acceptance test: Outputs are deterministic (stable IDs/fields), can be diffed in git, and can be schema-validated in CI.
- Version-aware retrieval
- Acceptance test: Generating
release/2.3pages cannot retrieve chunks frommain, even when names overlap.
- Acceptance test: Generating
- Citation artifacts
- Acceptance test: Each published page includes machine-readable citation payloads tied to commit + anchors.
If a tool can’t pass these tests in your environment, you’ll still end up relying on manual reviews to catch drift.
Next step: use the AI Documentation Pipeline Checklist
If you want to implement this without boiling the ocean, start with one module (e.g., Billing API) and follow this checklist:
- Define source-of-truth hierarchy + owners
- Pick index strategy (per-release or filtered single index)
- Create chunk template + metadata schema
- Enforce citation payload requirements
- Implement doc gates in CI (spec check, example check, link/anchor check)
- Set freshness SLAs and start measuring drift rate + median lag
Run it for one release line, get ACV scores stable, then replicate.
FAQ
How do you prevent hallucinations in AI documentation?
You reduce ungrounded outputs by using RAG with well-scoped chunks and enforcing citations tied to specific sources, plus verification checks and human review where needed. Write the Docs emphasizes that QA remains essential for reliable AI-assisted documentation (Write the Docs).
How do you version-control AI-generated docs?
Tie every generated page to a branch/tag/commit, enforce version metadata on chunks, and constrain retrieval by version (often via per-release indexes or strict metadata filters). Including version info in each independently understandable section is a key recommendation for AI-friendly documentation structure (kapa.ai).
How do you keep docs in sync with code changes?
Integrate doc generation and checks into CI/CD so updates are triggered by relevant commits and merges, then measure median doc lag and drift rate over time. Docsie describes integrating AI documentation workflows with repositories and automated triggers to keep documentation synchronized (Docsie).
How do you verify AI documentation against source code?
Use static checks (spec/schema comparison, symbol scanning, config validation) and, where safe, runtime checks (staging smoke tests). Treat the output like a PR and route review to code owners—human oversight is part of the model recommended by documentation communities (Write the Docs).
Should you use RAG or fine-tuning for documentation?
Use RAG when correctness and version specificity matter and you need citations to current sources. Consider fine-tuning when you need consistent formatting/style and have a controlled, licensed training set. In many teams, RAG + strong structure is the first win.
Sources / References
- AI Documentation: Definition, Examples & Best Practices (2025)
- AI Code Documentation: Benefits and Top Tips - IBM
- Writing documentation for AI: best practices | kapa.ai docs
- How to improve technical documentation with generative AI - InfoWorld
- Write the Docs AI Guide
- Atlassian Confluence AI Knowledge Base